Autonomous Research Loops: A Practical Operating Model for Lean Teams
Most teams exploring AI agents are stuck in a shallow loop: better prompts, more tools, same bottlenecks.
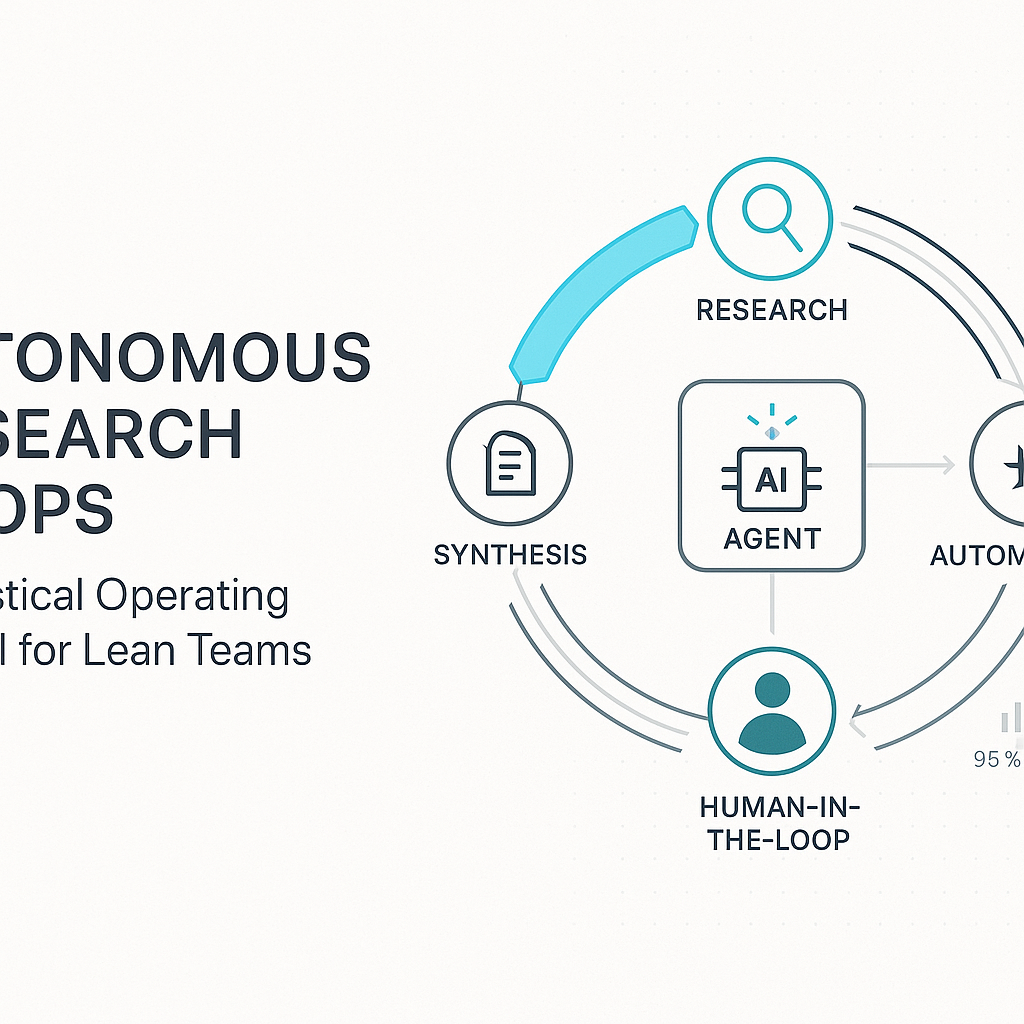
The shift happening now is operational, not just linguistic. The most useful pattern is an autonomous research loop: define a target, let agents run bounded experiments, review outputs, tighten constraints, and run again.
That sounds abstract until you look at real implementation choices. Andrej Karpathy's public autoresearch repo describes a simple but important setup: fixed five-minute experiment windows, tight feedback loops, and practical throughput on a single GPU. This is a strong signal that useful automation is increasingly available to small teams, not just labs with large clusters.
From there, the next challenge is coordination. One agent can run tasks. A team of agents can run a process.
Microsoft's AutoGen project is explicitly built around building event-driven, multi-agent systems. LangGraph's documentation makes a useful distinction: workflows are predictable code paths, while agents dynamically decide the next step. In practice, high-performing teams blend both.
A practical operating model looks like this:
1) Define one narrow business question
Pick one recurring decision with clear outcomes. Example: "Which outreach angle produces the highest booked-call rate this week?"
2) Set bounded experiments
Use strict limits on time, data sources, and token budget. Bounded runs are easier to audit and cheaper to iterate.
3) Separate roles by agent
Use role-specific agents for research, synthesis, and QA. Avoid one mega-agent that does everything poorly.
4) Keep a human decision gate
Agents generate options. Humans approve changes that affect brand, budget, or customer promises.
5) Log results and failures
Every run should produce reusable notes: what worked, what failed, and what to test next. This is how compounding happens.
Where teams go wrong:
- They start with broad goals instead of one measurable question.
- They over-index on model quality and under-invest in process design.
- They skip instrumentation, so they cannot tell whether the loop improved outcomes.
What to do this week:
- Choose one workflow with weekly repetition.
- Define one KPI and one guardrail.
- Run a seven-day autonomous loop with daily human review.
- Decide to scale, redesign, or kill the workflow based on evidence.
The real competitive edge is not "using AI." It is building a repeatable loop where experiments, learning, and decisions happen faster than before.
Source notes:
- Karpathy autoresearch repository: https://github.com/karpathy/autoresearch
- AutoGen repository: https://github.com/microsoft/autogen
- LangGraph workflows and agents docs: https://docs.langchain.com/oss/python/langgraph/workflows-agents
- X discussion examples: https://x.com/hooeem/status/2030734055180751179 and https://x.com/BrianRoemmele/status/2030730697141584270