A Free AI Model Is Not a Free Workflow
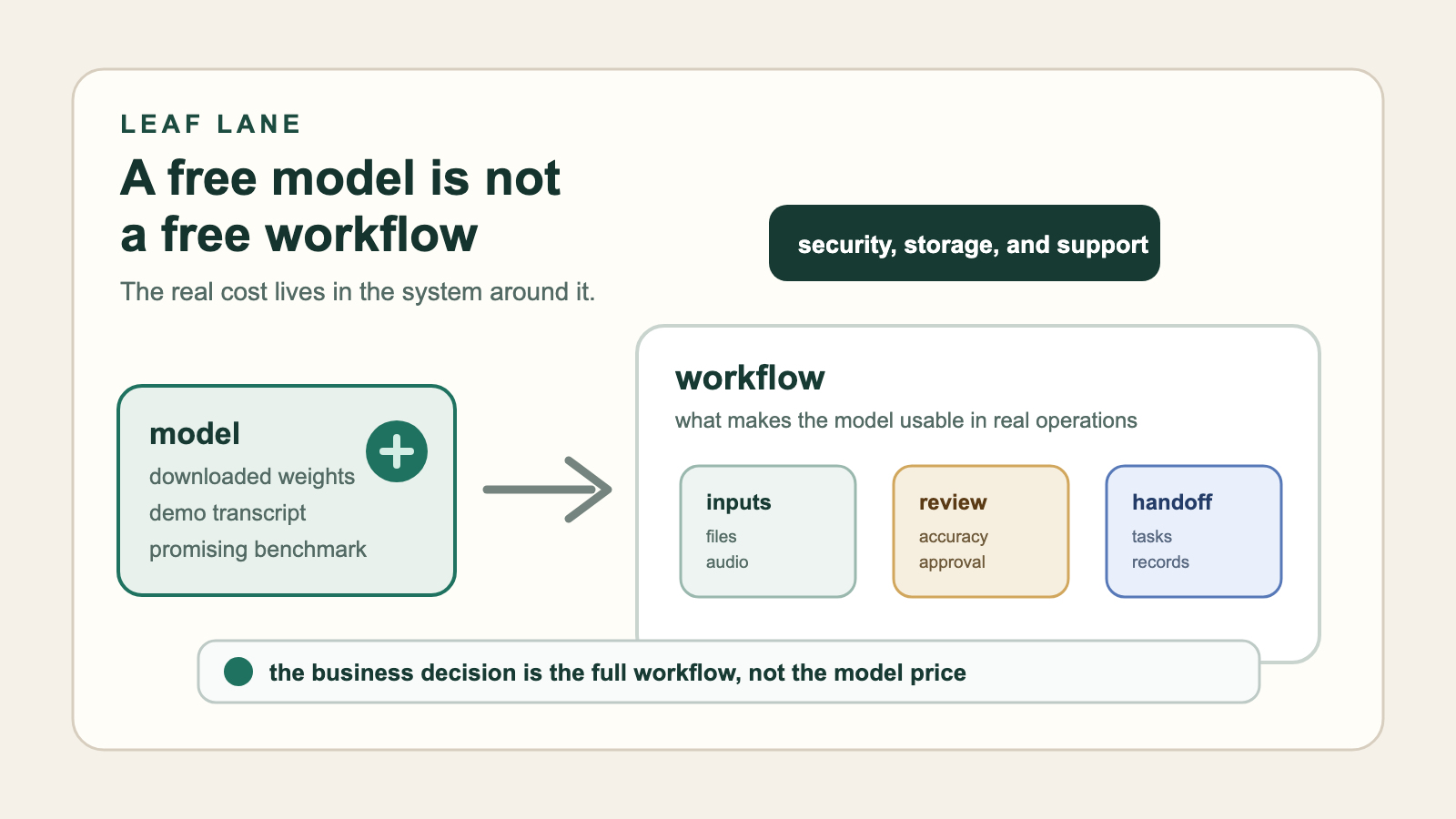
A free model can make a demo look like an easy decision. It does not make the business workflow free.
That is important because speech-to-text keeps getting cheaper and more capable. OpenAI lists transcription models with per-minute pricing, including gpt-4o-transcribe at $0.006 per minute and gpt-4o-mini-transcribe at $0.003 per minute. ElevenLabs lists Scribe speech-to-text pricing by the hour, with separate pricing for realtime use and add-ons. AssemblyAI lists usage-based speech-to-text pricing, including a $0.15 per hour base rate for several models and separate add-ons such as speaker diarization. Microsoft has also published VibeVoice-ASR, an MIT-licensed model that handles long-form transcription with speaker, timestamp, and content structure.
It is easy to look at those options and ask which one is cheapest.
For most operators, that is not the first question to answer.
The better question is this: what does the full voice workflow need to do, and who handles each part when something breaks?
The transcript is usually not the finished work
A transcript by itself rarely solves the business problem.
In practice, a useful voice workflow often has to do several jobs after the audio file exists:
- record or ingest the call
- store the audio in the right place
- identify speakers
- add timestamps
- remove sensitive details
- summarize the conversation
- pull out action items
- send notes into a CRM or ticket
- notify the next person in the process
- keep an audit trail for review
Think about a few common examples.
A sales team may want call notes pushed into the right CRM record with next steps attached. A support team may want call summaries routed into tickets for follow-up. A service business may want intake calls transcribed, tagged, and reviewed before an estimate gets sent. A recruiting team may want interview transcripts with speaker labels and a review step before notes are shared.
In each case, the transcript is one step in a larger operating process.
If the transcript is wrong, someone needs a way to fix it. If the summary misses a key commitment, someone needs a review loop. If the audio includes private customer or employee information, someone needs retention rules, access controls, and a deletion policy. If the workflow stops working, someone needs to know whether the issue came from the model, the hosting layer, the integration, or the source audio.
That is where the real cost sits.
A managed API usually buys you operating coverage
A managed API often includes more than raw transcription.
You are usually paying for some combination of:
- hosted infrastructure
- uptime and scaling
- account controls
- documentation
- billing and usage tracking
- rate limits
- support paths
- a stable integration pattern your team can maintain
That does not mean a managed provider is always the better choice. It means the invoice is covering part of the operating burden.
For a small or mid-sized business, that burden matters. A tool that costs more per hour of audio can still be the cheaper option if your team does not have to maintain servers, troubleshoot failed jobs, or build a manual recovery path every time an upload goes wrong.
An open model shifts work onto your team
An open model can lower or remove the per-minute API bill. That is real. It can also give you more control over where audio lives, how the workflow runs, and how outputs are shaped.
But the work does not disappear. It moves.
If you run the model yourself, you may need to handle:
- hosting and compute
- deployment work
- monitoring and alerts
- storage and bandwidth
- retries and queueing
- security review
- model updates
- integration maintenance
- the people who know how to keep it all healthy
That trade can make sense.
It is just not free.
When an open model is worth serious consideration
An open speech-to-text model is worth a close look when the workflow has enough volume, privacy sensitivity, or customization needs to justify owning more of the stack.
That tends to show up in situations like these:
- you process many hours of audio every week and usage costs are becoming a meaningful line item
- you need to keep audio inside your own infrastructure for privacy or policy reasons
- your calls include unusual vocabulary, product names, or industry terms that need custom handling
- you are building a product feature where marginal cost matters once usage becomes predictable
For example, an internal QA workflow for a large support team may justify more ownership if hundreds of hours of calls need to be processed each month. A healthcare-adjacent or legal workflow may care more about where audio is stored and who can access it. A field service business may want tighter control over how action items are extracted from noisy calls and sent into job records.
Those are reasonable reasons to test an open model.
But before replacing a managed workflow, answer a few practical questions:
- Can we run it reliably at the volume we expect?
- Can we measure accuracy on our own audio, not public sample clips?
- Can we produce the speaker labels, timestamps, summaries, and action items our team actually needs?
- Can we protect customer or employee data appropriately?
- Can a non-engineer tell what failed and what to do next?
- Can we explain the real monthly cost, including hosting and maintenance?
If those answers are weak, the model may still be useful for experiments. It may not be ready to run an important business process.
When a managed API is still the better decision
A managed provider often wins when speech-to-text matters, but running voice infrastructure is not part of your business.
That is common.
If your team needs meeting notes, customer-call summaries, podcast transcripts, interview review, or support-call tagging, the fastest workable path is often a managed service with predictable billing and fewer moving parts.
This is especially true for smaller teams that already have enough systems to maintain.
A technically cheaper setup can become an expensive one if it adds hidden work:
- engineers pulled into support issues
- operators stuck with manual cleanup
- managers reviewing inconsistent outputs
- security questions without clear answers
- no clear owner when the workflow breaks
If a managed service costs more per hour of audio but gives your team a reliable interface, a usable review path, and less maintenance, that may be the right trade.
Do the workflow math before the vendor math
Before switching from a paid transcription tool to a free or open model, map the workflow from start to finish.
Start with the source of the audio. Then list every step that has to happen before the output is useful to the business.
That often includes:
- upload or recording capture
- transcription
- speaker separation
- cleanup
- summary generation
- review and approval
- routing into a CRM, inbox, or ticket
- storage
- deletion or retention handling
- reporting
Then mark each step clearly:
- handled by the model
- handled by a provider
- handled by your team
- not yet defined
After that, estimate cost in three buckets:
- usage cost: minutes, hours, add-ons, storage, bandwidth
- operating cost: setup, hosting, monitoring, retries, updates, support
- human review cost: correction time, approval gates, exception handling, quality checks
That total is the price of the workflow.
Not the model. The workflow.
A better way to test the decision
For most small businesses, the cleanest starting point is one real use case.
Pick something concrete:
- sales-call notes
- customer-support summaries
- meeting follow-ups
- intake-call triage
- podcast transcripts
- training-library search
Then run the same sample audio through two or three options.
Compare the output based on the final work product your team needs, rather than transcript quality in isolation.
Check things like:
- Did it capture the right names, numbers, and commitments?
- Were speaker labels accurate enough to use?
- Did the summary save time or create review work?
- Could the result go straight into your CRM, ticket, or record?
- How easy was it to recover from a bad file or bad output?
That kind of pilot usually tells you more than a pricing page.
If a managed tool gives you clean enough output, low setup, and a review process your team can live with, use it. If volume, privacy, or customization makes the managed path too expensive or too limiting, test an open model inside a contained workflow with a clear owner.
The practical next step is simple: take one voice workflow your team already does every week, map every handoff around it, and price the labor around the transcript before you price the transcript itself.
Source notes: Pricing and capability references were checked against OpenAI API pricing, ElevenLabs API pricing, AssemblyAI pricing, Deepgram pricing and speech-to-text notes, Microsoft's VibeVoice repository, and the VibeVoice-ASR model card.